The Nature Conservancy Fisheries Monitoring
December 12, 2016Jocelyn Ong
Using machine learning algorithms to identify species of fish
Introduction
For my capstone, I decided to use the data provided in a Kaggle competition. The objective of the competition is to classify pictures based on the type(s) of fish present in it.
Motivation
The aim behind the project is to be able to identify if and when certain species of fishes are spotted on board of vessels - the named species are those where commercial fishing is restricted/ controlled, and this project ideally helps with the monitoring of such activities.
Marine conservation is a big topic in the SCUBA diving community, and as a SCUBA diver, I’m hoping that success in this competition will be able to contribute to that.
About the dataset
Due to a non-disclosure agreement required by The Nature Conservancy, I won’t be able to show you any of the pictures made available to us.
Our training data comes in the form of pictures - all of them are screenshots of video feeds from various fishing vessels. The training data has been labeled with the various classes, and that’s all we get.
There are 8 target classes:
- ALB: Albacore Tuna
- BET: Bigeye Tuna
- DOL: Dolphinfish/ Mahi-Mahi
- LAG: Opah/ Moonfish
- NoF: No fish
- OTHER: Other types of fish
- SHARK: Sharks
- YFT: Yellowfin Tuna
Problems, risks and assumptions
I faced several problems with this project, some were problems with me, and some were problems with the dataset.
- I have no experience with computer vision.
- This project consisted of a lot of self learning, experimenting with the code we learned during half a day of lecture, looking for more code relating to computer vision and talking through with the instructors and my peers who had also decided to tackle a computer vision project.
- Classes are not of the same size.
- Here’s a look at the number of pictures we had for each class:
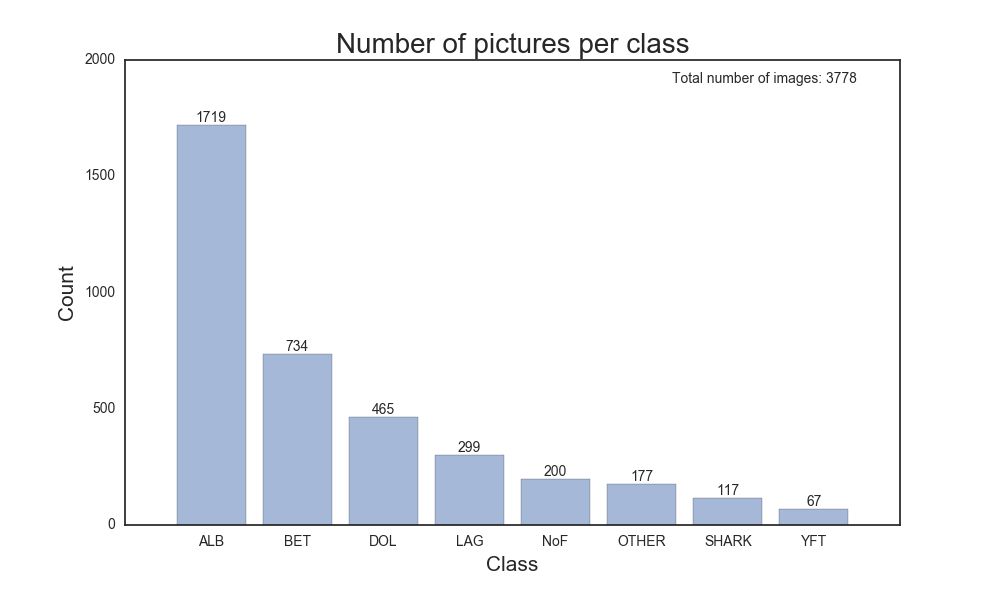
- Clearly, we have a lot of pictures for Albacore Tuna, and not a lot for Yellowfin Tuna
- Here’s a look at the number of pictures we had for each class:
- Sharks are diverse.
- This is where being a SCUBA diver helped (or didn’t). I clearly knew that sharks vary greatly from species to species - but it didn’t matter for this competition. It just wants to know whether or not there’s a shark on the vessel.
- That’s a lot of species to account for.
- This is where being a SCUBA diver helped (or didn’t). I clearly knew that sharks vary greatly from species to species - but it didn’t matter for this competition. It just wants to know whether or not there’s a shark on the vessel.
- Region is important
- Fishes can be regional and seasonal - having location and time data may increase the accuracy of the classification
- I am completely reliant on GraphLab.
- Due to my currently limited knowledge on computer vision, I used GraphLab’s Deep Feature Extractor to extract the features of each image.
- Deep Feature Extractor is a pre-trained algorithm - I don’t have any control over what features it is extracting but I’m assuming that they are useful features.
- Due to my currently limited knowledge on computer vision, I used GraphLab’s Deep Feature Extractor to extract the features of each image.
- Cosine similarity between and within classes
- In simple terms, cosine similarity measures the similarity between vectors.
- It ranges from 0 to 1, 1 being exactly the same.
- Each of our images can be thought of as a vector of its features
- Here’s the cosine similarity between classes:
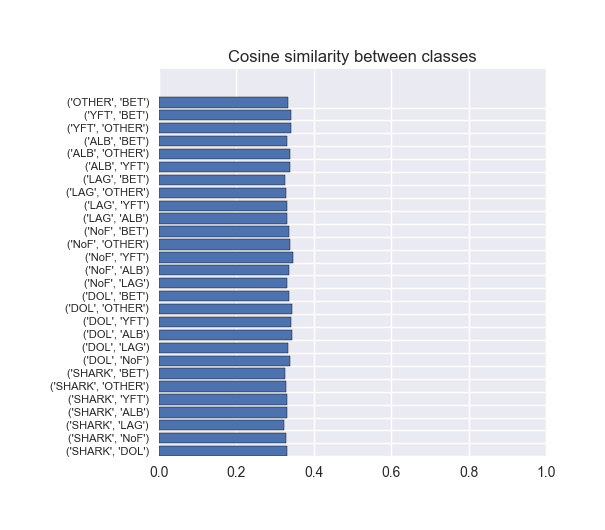
- That’s not too bad - images in different classes aren’t really similar to each other, we want that.
- But take a look at the cosine similarity within each class:
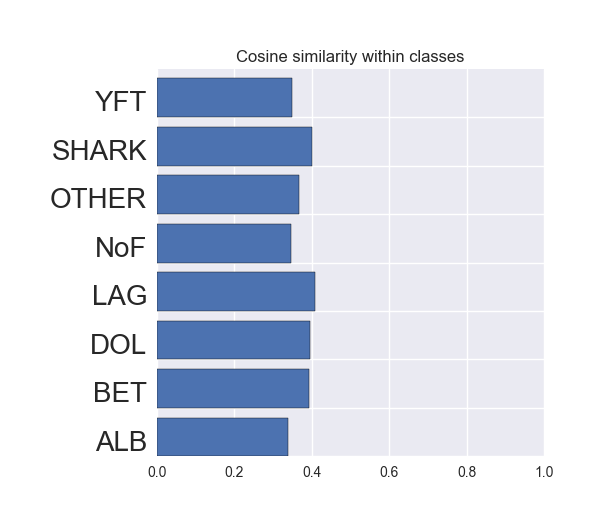
- That looks just like the similarity between classes - even images within the same class are not similar to each other.
- This may throw off our model.
- In simple terms, cosine similarity measures the similarity between vectors.
Approach
After much discussion on imbalanced learning, this was my approach to the project:
- For each picture, extract deep features.
- Combine class, file name, and deep features into a dataframe.
- Define features and target.
- Test various methods of balancing the classes.
- Undersampling
- Oversampling with bootstrapping
- Oversampling with SMOTE (Synthetic Minority Oversampling TEchnique)
- Alex pointed me to a great article on dealing with imbalanced classes
- Test different models.
- Pick the one with the best score.
- Pickle everything.
- Write a local Flask app to take in image URLs and return a predicted class.
Results
With a train test split, I managed to obtain an average accuracy score and an average F1 score of about 95% (for both). I was pretty happy with that. My Kaggle score wasn’t too shabby as well, XGBoost and SMOTE brought me up to about the 90th position (it’s slipped several positions since then).
I wanted to know how this would perform on random pictures of fishes - not too well actually. I guess it’s because we were training on the whole image, instead of just the fish.
Next steps
I would like to explore object detection before feature extraction - if we are able to pinpoint where the fish is in the picture, we should be able to extract the features of the fish, and not its surroundings.
Thanks for taking the time to read about my capstone - you can view my presentation on Prezi.
Back to top ↑“People ask: Why should I care about the ocean? Because the ocean is the cornerstone of earth’s life support system, it shapes climate and weather. It holds most of life on earth. 97% of earth’s water is there. It’s the blue heart of the planet-we should take care of our heart. It’s what makes life possible for us. We still have a really good chance to make things better than they are. They won’t get better unless we take the action and inspire others to do the same thing. No one is without power. Everybody has the capacity to do something.” – Sylvia Earle