Blackjack
March 16, 2017Jocelyn Ong
Blackjack - An initial look at the game
Progress
It’s been more than a month since I decided to explore data science, machine learning, and blackjack. Here’s a little look at where I am now.
Details of the dataset
I started out with the assumption that our game was played with a continuous shuffling machine, but then I decided that maybe we should also compare games where the deck isn’t shuffled in between hands.
So we’ve got 2 scenarios:
- Continuous shuffling machine: after each game, the cards are returned to the deck and randomly inserted into the deck
- No shuffling: the cards are tossed after each game, and we keep playing until we reach the ‘end’ of the deck
- We’ll set stop at about 10 cards: anytime the deck has less than 10 cards remaining before a play, we’ll start with a new deck
Exploratory data analysis
I started out just looking at the dataset numbers. How often do we win? What kind of points do we get dealt? What kind of points do we end up with? What kind of points does the dealer end up with?
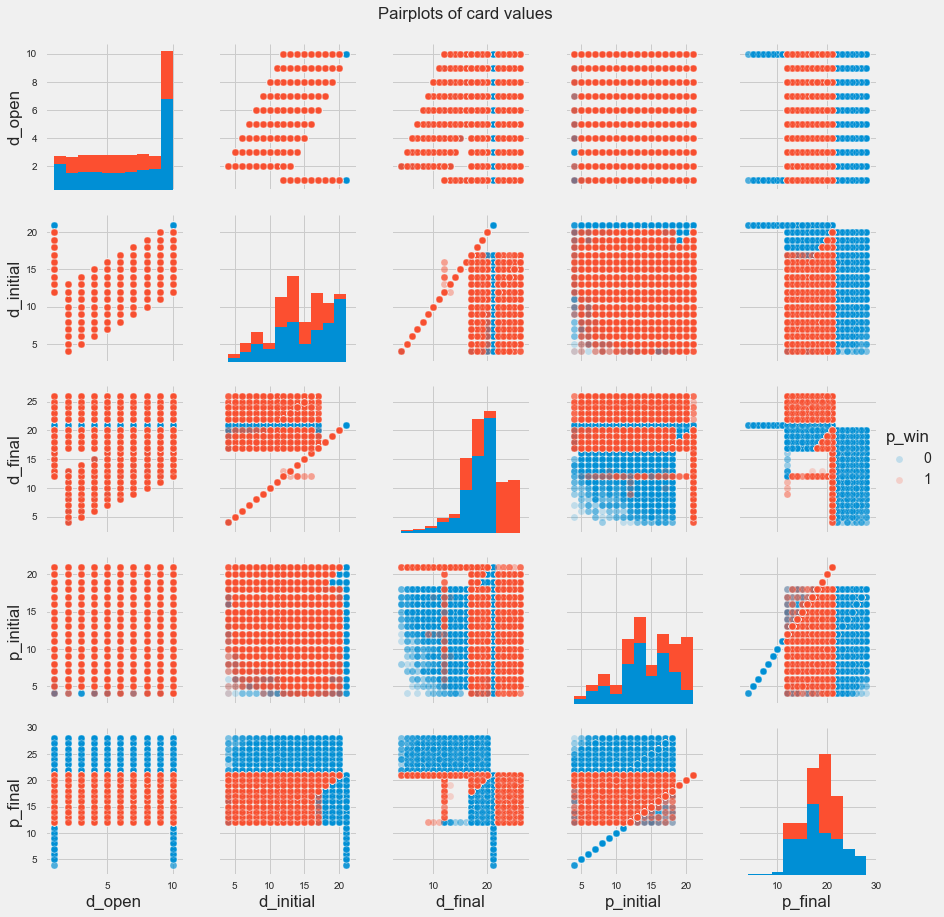
Based on our dataset, our winning rate wasn’t good, at around 40%. That is, out of all the games we played, we won about 40% of them.
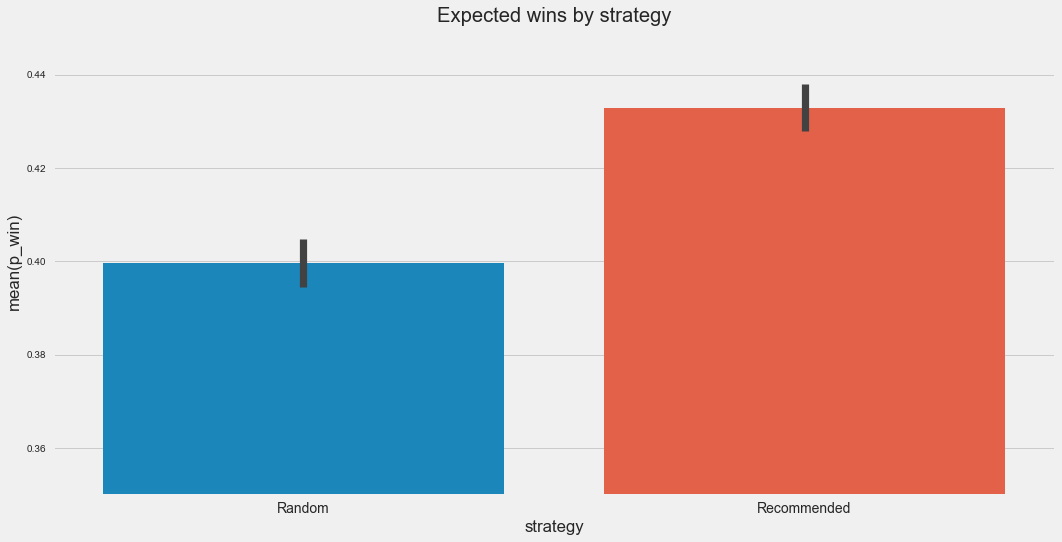
And if we split up the games by strategy, playing by the recommended strategy puts our expected wins at about 43%, and the random strategy at about 39%. That’s a pretty good start, so perhaps playing by the recommended strategy does indeed increase your chances of winning. (It’s still not good to me though, at under 50%.)
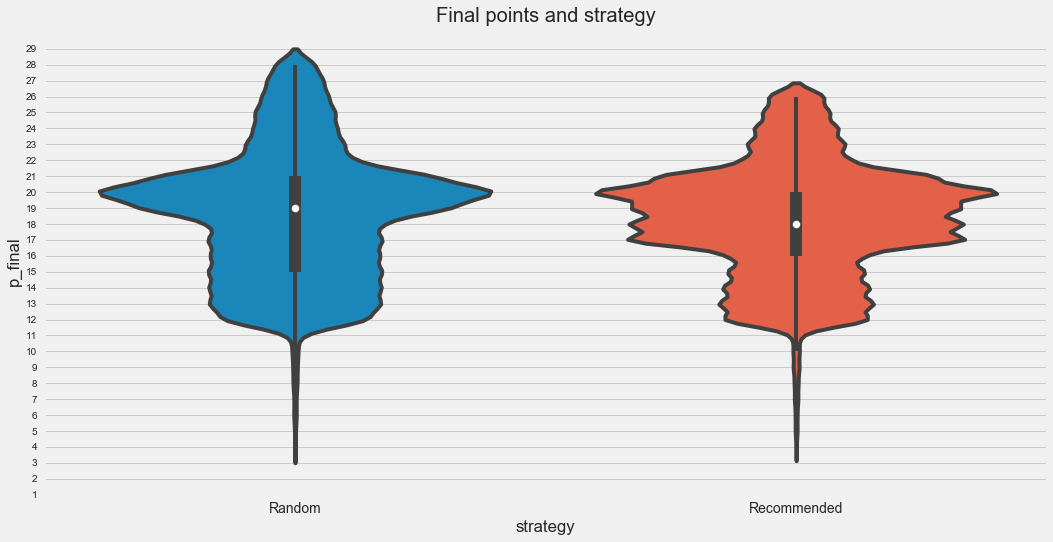
If we look at the distribution of points between the 2 strategies, we can see that there’s a higher likelihood of getting 17 to 20 points when you play the recommended strategy (the plot is wider), and a lower likelihood that you would bust.
Statistical testing
We saw that there’s a difference between playing the recommended strategy as compared to playing randomly, but it the difference ‘significant’?
So I did 1000 trials of 100 games, and plotted the results of those 1000 trials each for the recommended strategy and playing randomly.
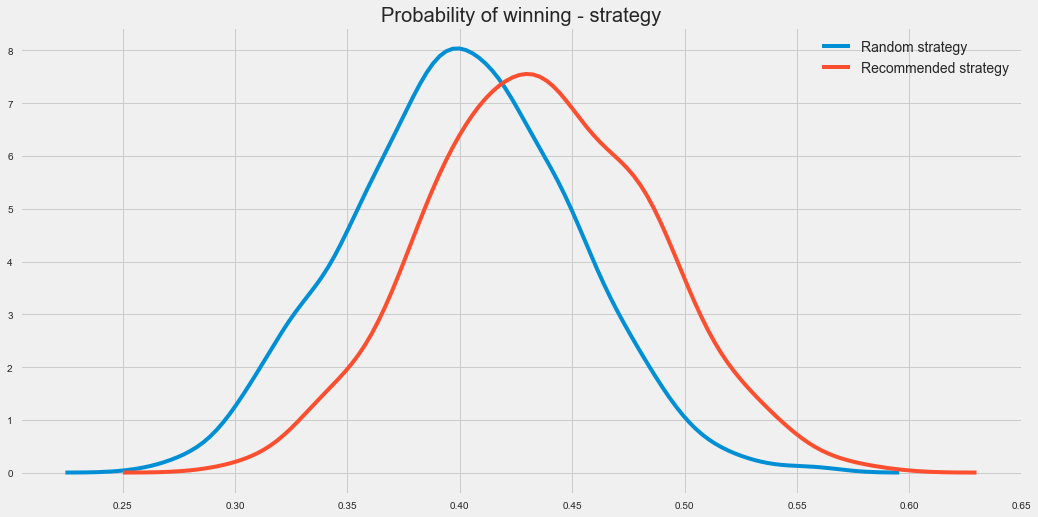
We see the same difference that we noted above, and if we do a 2 sample t-test, we get a p-value of less than 1%. (Actually, it’s so tiny that it’s much much smaller than 1%.) Based on this, it seems pretty certain that the recommended strategy is much better than playing randomly.
I also tried comparing games where continuous shuffling is practiced and games where there is no shuffling between games, but I think the function needs a bit of tweaking for proper comparison. I also looked at whether the dealer was required to hit on soft 17, and it doesn’t seem to have any significant effect on our win rates.
More?
I wanted to explore if we could find a strategy better than the recommended strategy, but I think to do that, we need to look at just the random games. And I mean completely random, not just the pseudo-random strategy that we used to compare the 2 strategies. So I’m off to tweak around with my functions to generate another dataset.
I’ll come back to this dataset time and again to play with it. The dataset is available on data science projects repo so feel free to download it (or the code to generate it) and play around with it.
What I learned from my first solo project
So this is the first “real” project that I looked at outside of the immersive, and there were so many learning points that came up.
- Simulation
- Not easy at all, there’s so much you need to consider even if you think you know exactly how everything is supposed to work
- Putting it into code means that you have to think of how you want to structure things, thinking of corner cases and dealing with them
- Coming up with questions to ask
- Sure it’s easy to ask a question, but is it interesting?
- Can we answer it?
- Answering our questions
- What data do we need, do we have it?
(I actually spent most of my time generating the dataset for this project, so maybe for the next one, I’ll look at one of the datasets available publicly.)
Back to top ↑