Credit Card Fraud
April 27, 2017Jocelyn Ong
Detecting credit card fraud cases using anonymized data
Introduction
Our dataset is obtained from Kaggle. The original data included information on transactions made by credit cards over 2 days in September 2013 by European cardholders. Due to confidentiality issues, the information has been transformed using PCA and no cardholder or transaction details (except amount) have been provided.
Our aim is to use classification methods to see if we can determine if a transaction is a fraudulent transaction based on the features provided.
TL;DR
Using various classification models, we tried to identify whether credit card transactions were fraudulent. We also built a 3 layer neural net to tackle the problem, and it did outperform other classification methods.
Because our features were the results of a principal component analysis, and because our dataset is not enormous, feature selection was not significantly helpful in terms of both performance and time. (Full feature set still gave better results with no significant loss of time.)
Efforts to balance the dataset also did not better our performance and instead caused precision to dip.
About the data
Classes
Our data has 2 classes: not fraudulent (class 0) and fraudulent (class 1). The dataset is highly imbalanced with only 492 fraudulent cases out of a total of 284,807 (~ 0.2%). In classification problems, this could pose a problem especially if our aim is solely to maximize accuracy. (But let’s see how it goes.)
Features
Most of our features don’t actually mean anything because they are the result of principal component analysis. We do have 2 features which did not undergo the transformation, time and amount.
Time refers to the number of seconds elapsed since the first event. Amount refers to the amount involved in the transaction.
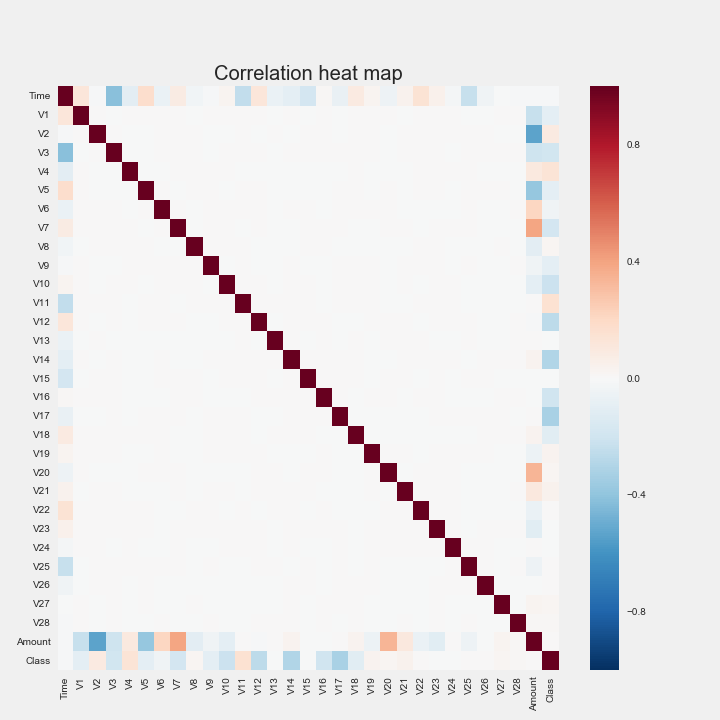
If we look at the correlation between the features (and the class label), we can see that there are several components which are correlated with amount, and several which have no correlation with the class labels at all. (Unfortunately, one of the features that have no correlation with the class labels is the amount involved in the transaction, which is strangely unintuitive to us.)
We will perform the classification with the full set of features and compare it to one where we try to do some feature selection to examine the trade offs between the two.
Modeling
There isn’t much cleaning to be done on the data (as with most Kaggle datasets). We simply split our data into training and testing sets, and scaled them.
For a start, we went with the full feature set, and simply did a plug and play into various classification models - logistic regression, naive bayes, random forest, adaboost (with logistic regression), and gradient boost.
In all our models, we had a 97% to 99% accuracy. But as we mentioned previously, accuracy doesn’t mean squat here because our dataset is highly skewed. So we take a look at our precision and recall scores.
- logistic regression and random forest did pretty well on both
- there were some misclassifications for both classes, but they were not significant in both cases
- naive bayes had really poor precision
- it was classifying a lot of non-fraudulent cases as fraudulent
- adaboost and gradient boost did fairly on both
- misclassification rate was higher than in logistic regression and random forest in terms of identifying fraud cases
- there were less misclassifications of non-fraudulent cases as fraud cases
Neural Nets
Well we didn’t do too poorly with some basic classification models. Then I got to thinking, how would a neural net fair on this?
I have been putting some time into understanding how neural nets work and how to implement them (tutorials seem to all be on the MNIST digits dataset), and this seemed like a good place to try out a basic neural net.
To keep things simple, neural nets are sort of like a whole bunch of linked switches, and they are arranged in layers. Our inputs make up the first layer, and the final layer is our output.
As an input, some switches will be turned on and some kept off. The links between the switches then decide whether the next layer of switches will be turned on, and it keeps moving until we reach the final layer. In a sense, we want to see if our first layer of switches are turned on in some combination, how will our final layer of switches look like?
I previously used Tensorflow but have been told that Keras might be easier to pick up. (While it was really easier for me to use Keras, I don’t know if it was because it was really easier, or because I already had some inkling because I had learned a little Tensorflow.)
Using keras, we set up a 3 layer neural net (the number of layers we want to use really depends on the dataset, and of course the computing power and time you have). With this neural net, we were able to increase both our precision and recall scores from before. We got better at identifying fraud cases, and we were less likely to misclassify non-fraudulent cases.
Feature Selection
Going back to our correlation table, we tried to remove some of the features which had no correlation with our class labels and features which a relatively high degree to correlation with another feature.
Because we were dealing with credit card transactions, it seemed logical to leave amount in (although based on the heatmap it looked like it had no correlation with the class label). And given that, we also kept features V8 to V18 (least correlation with amount, and some correlation with class).
Using these features did not significantly improve our run time and our results also suffered.
SMOTE
Because our classes were heavily imbalanced, we attempted to use the Synthetic Minority Oversampling TEchnique to balance the 2 classes. When we used this technique previously on another project, it greatly increased our predicting power, but in this case, it caused our precision to suffer for all methods tried previously.
If we think about credit card transactions, it is possibly because a fraudulent transaction is usually not too different from a normal one (if they were really different, they would be easily detected). By artificially synthesizing new “fraudulent” points, we might be inflating the number of points around a valid transaction and hence mask the actual nature of that transaction.
Round up
Even without knowing what our features are, we were able to quite accurately predict whether a credit card transaction was valid or fraudulent, with a high degree of both precision as recall. As we had guessed, the neural net performed the best, but it was at the expense of time. Given a much larger dataset, we may have to consider whether the trade off in time (if it is significant) is tolerable.
Thank you for reading this post! I had a lot of fun diving back into a project again after a brief hiatus and it was encouraging to see that implementing the neural net (which is not what I’m most familiar with) turned out very well and without any major hitches. You can view my notebook here.
Back to top ↑